Early Exploration into AI-Assisted Visual Analytics for Dynamic Videos
Abstract:
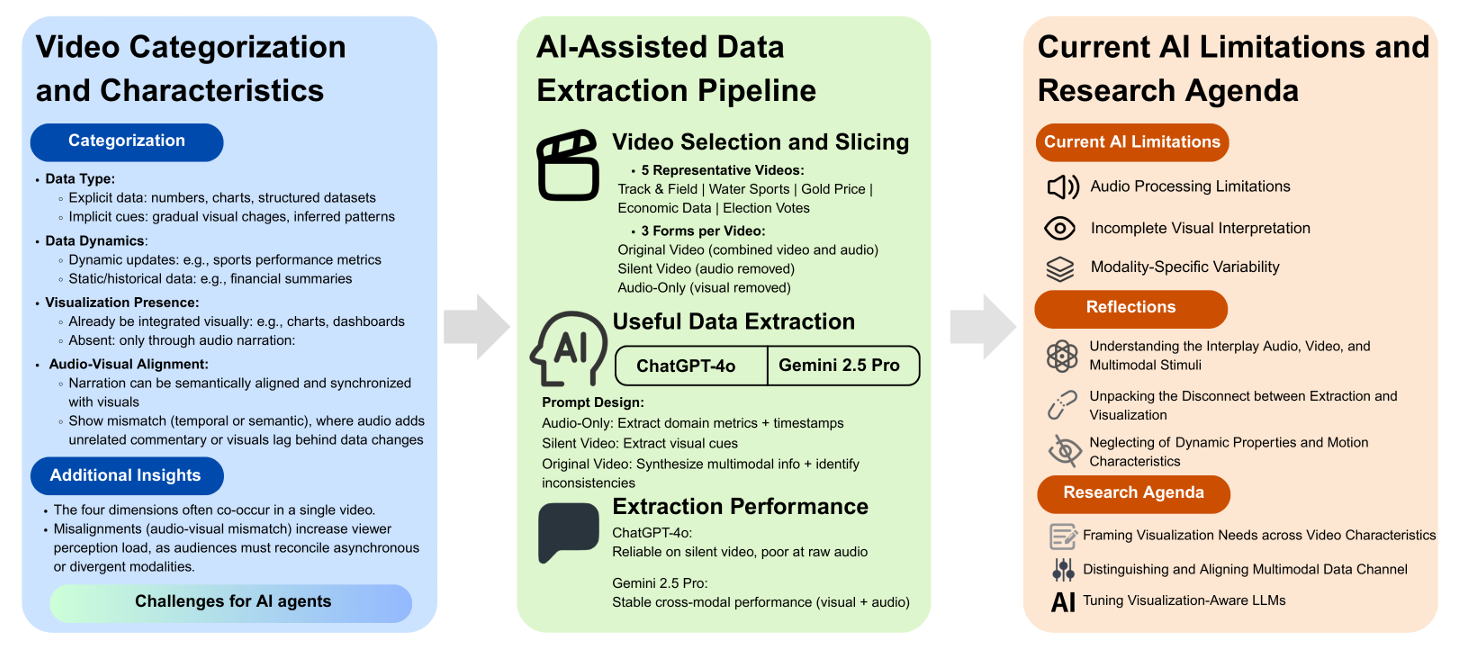
We present a preliminary investigation into the capabilities of current large language models (LLMs), i.e., ChatGPT and Gemini, in supporting visual analytics tasks for videos containing dynamically changing information. Videos are inherently multimodal, combining visual frames, audio narration, and sometimes text—often with inconsistencies or redundancies across channels—which poses challenges for reliable data extraction. While recent advances in video understanding have improved general-purpose AI performance, relatively little work has explored how generative AI can extract, prepare, and visualize data from videos through prompts, particularly where multimodal conflicts, dynamic updates, and moving entities are involved. To explore this space, we first categorize information-bearing videos along four dimensions: data type, data dynamics, visualization presence, and audio-visual alignment. We then apply LLMs to extract and structure information from representative video samples to support downstream visualization. We conclude with reflections and outline a research agenda for AI-assisted video-based visual analytics. Our OSF repository is at osf.io/ygn4c/.
BibTex:
@inproceedings{Qi:2025:EarlyExploration,
TITLE = {{Early Exploration into AI-Assisted Visual Analytics for Dynamic Videos}},
AUTHOR = {Qi, Guoy and Li, Junyi and Hong, Jiayi and Yao, Lijie},
BOOKTITLE = {{IEEE VIS Workshop on GenAI, Agents, and the Future of VIS}},
ADDRESS = {Vienna, Austria},
YEAR = {2025},
MONTH = Nov,
NOTE = {To appear},
DOI = {},
KEYWORDS = {visualization, video analysis, large language model},
PDF = {http://lijieyao.com/assets/pdf/Early_Exploration_into_AI-Assisted_Visual_Analytics_for_Dynamic_Videos.pdf},
}